Backpropagation
پس انتشار چیست؟
سیستم های یادگیری عمیق قادر به یادگیری الگوهای بسیار پیچیده هستند و این کار را با تنظیم وزن خود انجام می دهند. وزن یک شبکه عصبی عمیق دقیقاً چگونه تنظیم می شود؟
آنها از طریق فرآیندی به نام پس انتشار تنظیم می شوند ، بدون انتشار پس زمینه ؛ شبکه های عصبی عمیق قادر به انجام وظایفی مانند : تشخیص تصاویر و تفسیر زبان طبیعی نیستند. درک نحوه عملکرد پس انتشار برای درک شبکه های عصبی عمیق به طور کلی بسیار مهم است، بنابراین بیایید به پس انتشار بپردازیم و ببینیم چگونه از این فرآیند برای تنظیم وزن شبکه استفاده می شود.
درک پس انتشار ممکن است دشوار باشد و محاسباتی که برای انجام پس انتشار استفاده می شود می تواند بسیار پیچیده شود . این مقاله تلاش میکند تا با استفاده از ریاضیات پیچیده، درک شهودی از انتشار پسانداز به شما بدهد. با این حال برخی بحث ها در مورد ریاضیات پشت انتشار ضروری است.
هدف پس انتشار
بیایید با تعریف هدف پس انتشار شروع کنیم. وزن یک شبکه عصبی عمیق، قدرت اتصال بین واحدهای یک شبکه عصبی است. هنگامی که شبکه عصبی ایجاد می شود، فرضیاتی در مورد نحوه اتصال واحدهای یک لایه به لایه های متصل به آن ایجاد می شود. همانطور که داده ها از طریق شبکه عصبی حرکت می کنند، وزن ها محاسبه می شوند و مفروضاتی ساخته می شوند. هنگامی که داده ها به لایه نهایی شبکه می رسند، پیش بینی در مورد چگونگی ارتباط ویژگی ها با کلاس های مجموعه داده ، انجام می شود. تفاوت بین مقادیر پیشبینیشده و مقادیر واقعی، از دست دادن خطا است و هدف انتشار پسانداز کاهش تلفات است . این امر با تنظیم وزن شبکه انجام می شود و مفروضات را بیشتر شبیه روابط واقعی بین ویژگی های ورودی می کند.
آموزش شبکه عصبی عمیق
قبل از انتشار پسپشتی روی یک شبکه عصبی ، باید با آموزش منظم پیشرفت تا یک شبکه عصبی انجام شود. هنگامی که یک شبکه عصبی ایجاد می شود، مجموعه ای از وزن ها مقداردهی اولیه می شوند. با آموزش شبکه، ارزش وزنه ها تغییر خواهد کرد. عبور آموزش رو به جلوی یک شبکه عصبی را می توان به عنوان سه مرحله مجزا در نظر گرفت: فعال سازی نورون، انتقال نورون و انتشار به جلو.
هنگام آموزش یک شبکه عصبی عمیق، باید از چندین توابع ریاضی استفاده کنیم. نورون ها در یک شبکه عصبی عمیق از داده های ورودی و یک تابع فعال سازی تشکیل شده اند که مقدار لازم برای فعال سازی گره را تعیین می کند. مقدار فعالسازی یک نورون با چندین مؤلفه محاسبه میشود که مجموع وزنی ورودیها هستند. وزن ها و مقادیر ورودی به شاخص گره هایی که برای محاسبه فعال سازی استفاده می شوند بستگی دارد. هنگام محاسبه مقدار فعال سازی باید عدد دیگری را در نظر گرفت، یک مقدار بایاس . مقادیر بایاس نوسان ندارند ، بنابراین با وزن و ورودی ها ضرب نمی شوند، بلکه فقط اضافه می شوند. همه اینها به این معنی است که از معادله زیر می توان برای محاسبه مقدار فعال سازی استفاده کرد:
فعال سازی = جمع (وزن * ورودی) + تعصب
پس از فعال شدن نورون، از یک تابع فعال سازی برای تعیین خروجی ، خروجی واقعی نورون استفاده می شود. توابع فعال سازی مختلف برای کارهای متفاوت یادگیری بهینه هستند، اما توابع فعال سازی رایج شامل تابع سیگموئید، تابع Tanh و تابع ReLU هستند.
هنگامی که خروجی های نورون با اجرای مقدار فعال سازی از طریق تابع فعال سازی مورد نظر محاسبه می شود ، انتشار رو به جلو انجام می شود . انتشار رو به جلو فقط گرفتن خروجی های یک لایه و تبدیل آنها به ورودی لایه بعدی است . سپس از ورودی های جدید برای محاسبه توابع فعال سازی جدید استفاده
می شود و خروجی این عملیات به لایه زیر منتقل می گردد ؛ این روند تا انتهای شبکه عصبی ادامه دارد.
پس انتشار در شبکه
فرآیند پس انتشار تصمیمات نهایی پاس آموزشی یک مدل را می گیرد و سپس خطاهای این تصمیمات را مشخص می کند. خطاها با تضاد خروجی های تصمیمات شبکه و خروجی های مورد انتظار ، مطلوب شبکه محاسبه می شوند.
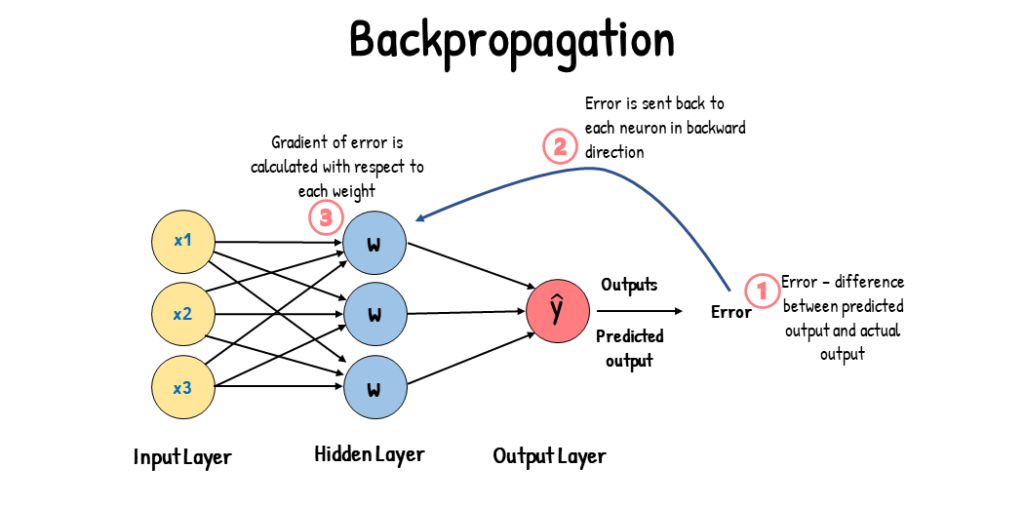
هنگامی که خطاهای تصمیمات شبکه محاسبه شد ، این اطلاعات از طریق شبکه منتشر می شود و پارامترهای شبکه در طول مسیر تغییر می کنند. روشی که برای بهروزرسانی وزنهای شبکه استفاده میشود ، بر مبنای حساب دیفرانسیل و انتگرال است ، به طور خاص ، بر اساس قانون زنجیرهای است . با این حال ، درک حساب دیفرانسیل و انتگرال برای درک ایده پس انتشار ضروری نیست . فقط بدانید که وقتی یک مقدار خروجی از یک نورون ارائه می شود ، شیب مقدار خروجی با یک تابع انتقال محاسبه می گردد و یک خروجی مشتق شده را تولید می کند . هنگام انجام پس انتشار ، خطای یک نورون خاص طبق فرمول زیر محاسبه می شود :
error = (expected_output – actual_output) * شیب مقدار خروجی نورون
هنگام کار بر روی نورون ها در لایه خروجی ، از مقدار کلاس به عنوان مقدار مورد انتظار استفاده می شود . پس از محاسبه خطا ، خطا به عنوان ورودی برای نورون های لایه پنهان استفاده می گردد ؛ به این معنی است که خطای این لایه پنهان ، خطاهای وزنی نورون های موجود در لایه خروجی است و محاسبات خطا از طریق شبکه در امتداد شبکه وزن به عقب حرکت می کند.
پس از محاسبه خطاهای شبکه ، وزن های موجود در شبکه باید به روز شوند . همانطور که گفته شد، محاسبه خطا شامل تعیین شیب مقدار خروجی است . پس از محاسبه شیب ، می توان از فرآیندی به نام گرادیان نزول برای تنظیم وزن ها در شبکه استفاده کرد . گرادیان شیبی است که زاویه شیب آن قابل اندازه گیری است . شیب با ترسیم “y over” یا “slear” بر روی “run” محاسبه می شود . در مورد شبکه عصبی و میزان خطا ، “y” خطای محاسبه شده است ، در حالی که “x” پارامترهای شبکه است . پارامترهای شبکه با مقادیر خطای محاسبه شده رابطه دارند و با تنظیم وزن شبکه ، خطا افزایش یا کاهش می یابد .
“Gradient Descent” فرآیند به روز رسانی وزنه ها است تا میزان خطا کاهش یابد . پس انتشار برای پیش بینی رابطه بین پارامترهای شبکه عصبی و نرخ خطا استفاده می شود که شبکه را برای نزول گرادیان تنظیم می کند . آموزش یک شبکه با نزول گرادیان شامل محاسبه وزن ها از طریق انتشار رو به جلو ، انتشار معکوس خطا و سپس به روز رسانی وزن های شبکه برای نزول گرادیان تنظیم می کند .
https://www.unite.ai/what-is-backpropagation/