Autoencoder
Autoencoder ( رمز گذار خودکار ) چیست؟
اگر قبلاً در مورد تکنیکهای یادگیری بدون نظارت خواندهاید ، ممکن است با اصطلاح « رمزگذار خودکار » برخورد کرده باشید. رمزگذارهای خودکار یکی از راه های اصلی توسعه مدل های یادگیری بدون نظارت هستند. اما رمزگذار خودکار دقیقاً چیست؟
به طور خلاصه، رمزگذارهای خودکار با دریافت داده، فشرده سازی و رمزگذاری داده ها و سپس بازسازی داده ها از نمایش رمزگذاری عمل می کنند. این مدل تا زمانی آموزش داده میشود که تلفات به حداقل برسد و دادهها تا حد امکان نزدیکتر بازتولید شوند. از طریق این فرآیند، رمزگذار خودکار میتواند ویژگیهای مهم دادهها را بیاموزد. در حالی که این یک تعریف سریع از رمزگذار خودکار است، نگاهی دقیق تر به رمزگذارهای خودکار و درک بهتر نحوه عملکرد آنها مفید خواهد بود. این مقاله سعی خواهد کرد رمزگشاهای خودکار را رمزگشایی کند و معماری رمزگذارهای خودکار و کاربردهای آنها را توضیح دهد.
Autoencoder چیست؟
رمزگذارهای خودکار شبکه های عصبی هستند. شبکه های عصبی از چندین لایه تشکیل شده اند و جنبه تعیین کننده رمزگذار خودکار این است که لایه های ورودی دقیقاً به اندازه لایه خروجی اطلاعات دارند. دلیل اینکه لایه ورودی و لایه خروجی دقیقاً تعداد واحدهای یکسانی دارند این است که رمزگذار خودکار قصد دارد داده های ورودی را تکرار کند ؛ پس از تجزیه و تحلیل داده ها و بازسازی آن به صورت بدون نظارت، یک کپی از داده ها را خروجی می دهد.
دادههایی که از طریق رمزگذار خودکار حرکت میکنند ، فقط مستقیماً از ورودی به خروجی نگاشته نمیشوند ؛ به این معنی که شبکه فقط دادههای ورودی را کپی نمیکند. سه جزء برای رمزگذار خودکار وجود دارد: بخش رمزگذاری (ورودی) که داده ها را فشرده می کند، مؤلفه ای است که داده های فشرده شده (یا گلوگاه) را مدیریت می کند و بخش رمزگشا (خروجی) هنگامی که داده ها به یک رمزگذار خودکار وارد می شوند، کدگذاری می شود و سپس به اندازه کوچکتر فشرده می گردند . سپس شبکه بر روی دادههای کدگذاری فشردهشده آموزش داده میشود و بازآفرینی آن دادهها را خروجی میدهد.
پس چرا می خواهید یک شبکه را طوری آموزش دهید که فقط داده هایی را که به آن داده می شود بازسازی کند؟ دلیل آن این است که شبکه “ماهیت” یا مهمترین ویژگی های داده های ورودی را می آموزد. پس از آموزش شبکه، می توان مدلی ایجاد کرد که می تواند داده های مشابه را با اضافه یا تفریق ویژگی های هدف خاص ترکیب کند. به عنوان مثال، میتوانید یک رمزگذار خودکار روی تصاویر دانهدار آموزش دهید و سپس از مدل آموزشدیده برای حذف دانهها و نویز از تصویر استفاده کنید.
معماری رمزگذار خودکار
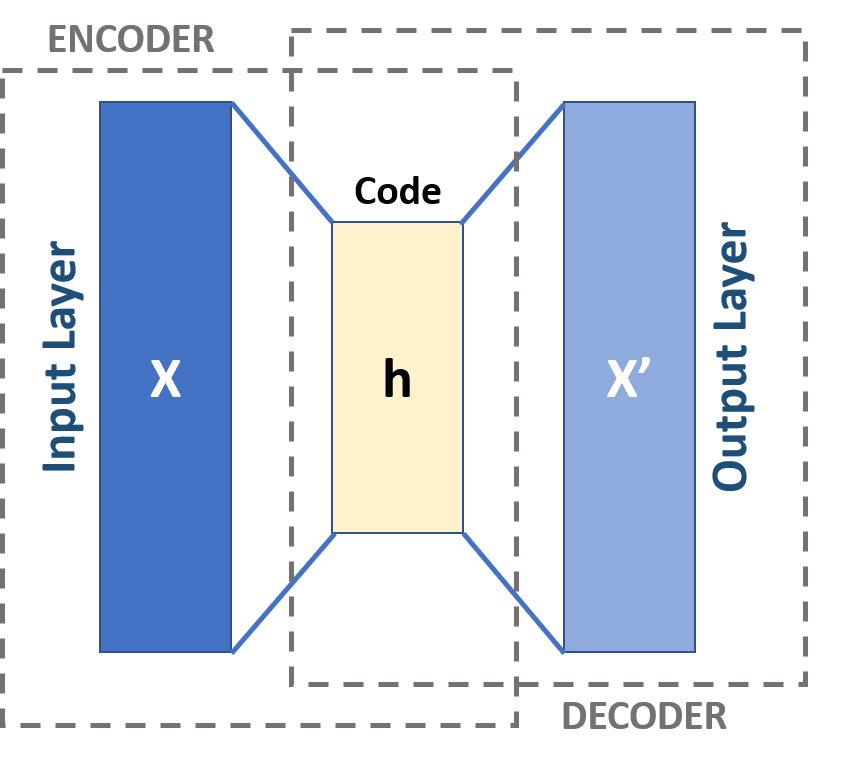
بیایید نگاهی به معماری یک رمزگذار خودکار بیندازیم. ما در اینجا به معماری اصلی یک رمزگذار خودکار می پردازیم. تغییراتی در این معماری کلی وجود دارد که در بخش زیر به آنها خواهیم پرداخت.
.
همانطور که قبلاً ذکر شد، رمزگذار خودکار اساساً می تواند به سه بخش مختلف تقسیم شود: رمزگذار، گلوگاه و رمزگشا.
بخش رمزگذار خودکار ، معمولاً یک شبکه متصل و متراکم است. هدف لایههای کدگذاری این است که دادههای ورودی را گرفته و آنها را در یک فضای پنهان فشرده کنند و نمایش جدیدی از دادهها ایجاد کنند که ابعاد آن کاهش یافته است.
لایه های کد، یا گلوگاه، با نمایش فشرده داده ها سروکار دارند. کد گلوگاه به دقت طراحی شده است تا مرتبطترین بخشهای دادههای مشاهدهشده را تعیین کند، یا ویژگیهای دادهها را که برای بازسازی مهمترین هستند، به روشی دیگر بیان کند. هدف در اینجا تعیین این است که کدام جنبه از داده ها باید حفظ شود و کدام یک را می توان دور انداخت. کد تنگنا باید دو ملاحظۀ مختلف را متعادل کند: اندازه نمایش (چقدر نمایش فشرده است) و ارتباط متغیر ، ویژگی Bottleneck فعال سازی عناصر را بر روی وزن ها و سوگیری های شبکه انجام می دهد. لایه گلوگاه گاهی اوقات بازنمایی پنهان یا متغیرهای پنهان نیز نامیده می شود.
لایه رمزگشا چیزی است که وظیفه گرفتن داده های فشرده و تبدیل آن ها به نمایشی با ابعاد مشابه داده های اصلی و بدون تغییر را بر عهده دارد. تبدیل با نمایش فضای پنهانی که توسط رمزگذار ایجاد شده است انجام می شود.
اساسی ترین معماری یک رمزگذار خودکار یک معماری پیشخور است، با ساختاری بسیار شبیه یک پرسپترون تک لایه که در پرسپترون های چندلایه استفاده می شود. همانند شبکههای عصبی پیشخور معمولی، رمزگذار خودکار با استفاده از انتشار آموزش داده میشود.
ویژگی های رمزگذار خودکار
انواع مختلفی از رمزگذارهای خودکار وجود دارد، اما همه آنها ویژگی های خاصی دارند که آنها را متحد می کند.
رمزگذارهای خودکار به طور خودکار یاد می گیرند. آنها نیازی به برچسب ندارند، و اگر داده های کافی به آنها داده شود، دریافت رمزگذار خودکار برای دستیابی به عملکرد بالا در نوع خاصی از
داده های ورودی آسان است.
رمزگذارهای خودکار مختص داده ها هستند. این بدان معنی است که آنها فقط می توانند داده هایی را فشرده کنند که بسیار شبیه به داده هایی هستند که رمزگذار خودکار قبلاً روی آنها آموزش دیده است. رمزگذارهای خودکار نیز دارای تلفات هستند، به این معنی که خروجی های مدل در مقایسه با داده های ورودی کاهش می یابد.
هنگام طراحی رمزگذار خودکار، مهندسان یادگیری ماشین باید به چهار فراپارامتر مدل های مختلف توجه کنند: اندازه کد، تعداد لایه، گرهها در هر لایه، و تابع از دست دادن.
اندازه کد تعیین می کند که چه تعداد گره قسمت میانی شبکه را شروع می کنند و تعداد گره های کمتری داده ها را فشرده تر می کنند. در یک رمزگذار خودکار عمیق، در حالی که تعداد لایهها میتواند هر عددی باشد که مهندس مناسب بداند، تعداد گرهها در یک لایه باید با ادامه رمزگذار کاهش یابد. در همین حال، برعکس در رمزگشا صادق است، به این معنی که تعداد گره ها در هر لایه باید با نزدیک شدن لایه های رمزگشا به لایه نهایی افزایش یابد. در نهایت، تابع از دست دادن یک رمزگذار خودکار معمولاً آنتروپی متقاطع باینری یا میانگین مربعات خطا است. آنتروپی متقاطع باینری برای مواردی مناسب است که مقادیر ورودی داده ها در محدوده 0 تا 1 قرار دارند.
انواع رمزگذار خودکار
همانطور که در بالا ذکر شد، تغییراتی در معماری کلاسیک رمزگذار خودکار وجود دارد. بیایید معماری های مختلف رمزگذار خودکار را بررسی کنیم.
پراکنده
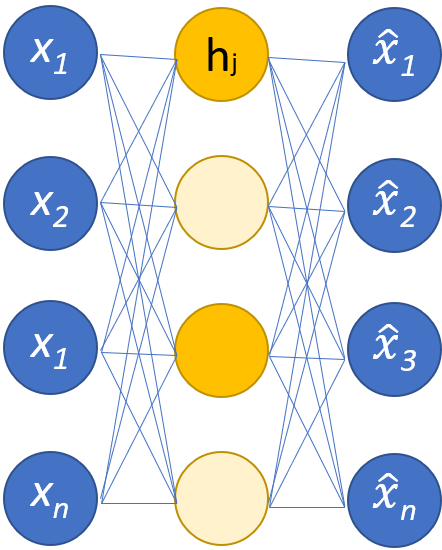
در حالی که رمزگذارهای خودکار معمولاً دارای یک گلوگاه هستند که داده ها را از طریق کاهش گره ها فشرده می کند، رمزگذارهای خودکار پراکنده جایگزینی برای فرمت عملیاتی معمولی هستند. در یک شبکه پراکنده، لایههای پنهان همان اندازه لایههای رمزگذار و رمزگشا را حفظ میکنند. در عوض، فعالسازیها در یک لایه معین جریمه میشوند و آن را تنظیم میکنند تا تابع ضرر بهتر ویژگیهای آماری دادههای ورودی را ثبت کند. به بیان دیگر، در حالی که لایههای پنهان یک رمزگذار خودکار پراکنده واحدهای بیشتری نسبت به یک رمزگذار خودکار سنتی دارند، تنها درصد مشخصی از آنها در هر لحظه فعال هستند. تاثیرگذارترین توابع فعال سازی حفظ می شوند و بقیه نادیده گرفته می شوند، و این محدودیت به شبکه کمک می کند تا تنها برجسته ترین ویژگی های داده های ورودی را تعیین کند.
انقباضی
رمزگذارهای خودکار انقباضی به گونهای طراحی شدهاند که در برابر تغییرات کوچک در دادهها انعطافپذیر باشند و نمایشی ثابت از دادهها را حفظ کنند. این با اعمال جریمه برای تابع ضرر انجام می شود. این تکنیک منظم سازی بر اساس هنجار فروبنیوس ماتریس ژاکوبین برای فعال سازی رمزگذار ورودی است. اثر این تکنیک منظم سازی این است که مدل مجبور می شود یک رمزگذاری بسازد که در آن ورودی های مشابه دارای رمزگذاری های مشابه باشند.
کانولوشنال
رمزگذارهای خودکار کانولوشن ، داده های ورودی را با تقسیم داده ها به بخش های فرعی و سپس تبدیل این زیربخش ها به سیگنال های ساده ای که برای ایجاد یک نمایش جدید از داده ها با هم جمع می شوند، رمزگذاری می کنند. مشابه شبکه های عصبی کانولوشن، رمزگذار خودکار کانولوشن در یادگیری داده های تصویر تخصص دارد و از فیلتری استفاده می کند که در کل تصویر بخش به بخش جابجا می شود. رمزگذاری های ایجاد شده توسط لایه رمزگذاری می تواند برای بازسازی تصویر، انعکاس تصویر یا اصلاح هندسه تصویر استفاده شود. هنگامی که فیلترها توسط شبکه آموخته شدند، می توان از آن ها در هر ورودی به اندازه کافی مشابه برای استخراج ویژگی های تصویر استفاده کرد.
نویز زدایی

انکودرهای خودکار حذف نویز نویز را به رمزگذاری وارد می کنند که منجر به کدگذاری می شود که نسخه خراب داده های ورودی اصلی است. این نسخه خراب داده برای آموزش مدل استفاده می شود، اما تابع ضرر مقادیر خروجی را با ورودی اصلی مقایسه می کند و نه ورودی خراب. هدف این است که شبکه بتواند نسخه اصلی و بدون خرابی تصویر را بازتولید کند. با مقایسه دادههای خراب با دادههای اصلی، شبکه میآموزد که کدام ویژگیهای داده مهمتر و کدام ویژگیها بیاهمیت/فساد هستند. به عبارت دیگر، برای اینکه یک مدل تصاویر خراب را حذف کند، باید ویژگی های مهم داده های تصویر را استخراج کرده باشد.
متغیر
رمزگذارهای خودکار متغیر با ایجاد فرضیاتی در مورد نحوه توزیع متغیرهای پنهان داده ها عمل می کنند. رمزگذار خودکار متغیر، توزیع احتمالی را برای ویژگیهای مختلف تصاویر آموزشی/ویژگیهای پنهان تولید میکند. هنگام آموزش، رمزگذار توزیع های پنهانی را برای ویژگی های مختلف تصاویر ورودی ایجاد می کند.

از آنجایی که مدل به جای مقادیر گسسته، ویژگی ها یا تصاویر را به عنوان توزیع گاوسی یاد می گیرد، می تواند برای تولید تصاویر جدید استفاده شود. توزیع گاوسی برای ایجاد یک بردار نمونه برداری می شود، که به شبکه رمزگشایی وارد می شود، که تصویری را بر اساس این بردار نمونه ها ارائه می دهد. اساساً، مدل ویژگی های مشترک تصاویر آموزشی را می آموزد و احتمال وقوع آنها را به آنها اختصاص می دهد. سپس می توان از توزیع احتمال برای مهندسی معکوس یک تصویر استفاده کرد و تصاویر جدیدی را که شبیه تصاویر اصلی و آموزشی است تولید کرد.
هنگام آموزش شبکه، داده های رمزگذاری شده تجزیه و تحلیل می شود و مدل شناسایی دو بردار را خروجی می دهد و میانگین و انحراف استاندارد تصاویر را ترسیم می کند. یک توزیع بر اساس این مقادیر ایجاد می شود. این برای حالت های پنهان مختلف انجام می شود. سپس رمزگشا نمونه های تصادفی را از توزیع مربوطه می گیرد و از آنها برای بازسازی ورودی های اولیه شبکه استفاده می کند.
برنامه های Autoencoder
رمزگذارهای خودکار را می توان برای طیف گسترده ای از برنامه ها استفاده کرد ، اما آنها معمولاً برای کارهایی مانند کاهش ابعاد، حذف نویز داده ها، استخراج ویژگی، تولید تصویر، پیش بینی ترتیب به ترتیب و سیستم های توصیه استفاده می شوند.
حذف نویز داده ها استفاده از رمزگذارهای خودکار برای حذف دانه / نویز از تصاویر است. به طور مشابه، رمزگذارهای خودکار را می توان برای ترمیم انواع آسیب های دیگر تصویر، مانند تصاویر تار یا تصاویر فاقد بخش، استفاده کرد. کاهش ابعاد می تواند به شبکه های با ظرفیت بالا کمک کند تا ویژگی های مفید تصاویر را بیاموزند، به این معنی که رمزگذارهای خودکار می توانند برای تقویت آموزش انواع دیگر شبکه های عصبی استفاده شوند. این در مورد استفاده از رمزگذارهای خودکار برای استخراج ویژگی نیز صادق است، زیرا رمزگذارهای خودکار می توانند برای شناسایی ویژگی های مجموعه داده های آموزشی دیگر برای آموزش مدل های دیگر استفاده شوند.
از نظر تولید تصویر، از رمزگذارهای خودکار میتوان برای تولید تصاویر انسانی جعلی یا شخصیتهای متحرک استفاده کرد که در طراحی سیستمهای تشخیص چهره یا خودکار کردن جنبههای خاصی از انیمیشن کاربرد دارد.
از مدلهای پیشبینی توالی به ترتیب میتوان برای تعیین ساختار زمانی دادهها استفاده کرد، به این معنی که رمزگذار خودکار میتواند برای تولید بعدی حتی در یک دنباله استفاده شود. به همین دلیل می توان از رمزگذار خودکار برای تولید فیلم استفاده کرد. در نهایت، رمزگذارهای خودکار عمیق را میتوان برای ایجاد سیستمهای توصیه با انتخاب الگوهای مربوط به علاقه کاربر، با رمزگذار تجزیه و تحلیل دادههای تعامل کاربر و رمزگشا ایجاد توصیههایی متناسب با الگوهای ایجاد شده استفاده کرد.
https://www.unite.ai/what-is-an-autoencoder/